How Video Encoding Works?

Video content is an integral part of our daily lives, permeating various forms of digital communication, entertainment, and education. As we increasingly rely on the internet for accessing news, social interactions, and multimedia, the efficiency of how video is transmitted and received becomes crucial. This reliance underscores the importance of understanding video encoding— the technology that enables the conversion of raw video files into formats that are easier to distribute, store, and stream across different platforms and devices. This introduction will delve into the fundamentals of video encoding, exploring its necessity due to the vast amount of data involved in video files, and examining the technologies that help compress and deliver video content efficiently to end-users worldwide. Whether for streaming your favorite TV show, participating in a video conference, or uploading content to social media, video encoding plays a pivotal role in how smoothly and quickly these activities can be performed.
What is video encoding
The process of encoding an image, in short, involves converting the original signal (data) into a format that can be redistributed. This stems from a very simple fact—the amount of data that even a standard web camera collects each second is enormous, and it cannot be effectively transmitted without compression. To illustrate this, let’s use a practical example and a bit of math.
A typical web camera found in an average laptop has a resolution of 720p, which means 1280×720 pixels (the first number is the horizontal pixel count, the second the vertical). Multiplying these values gives us exactly 921,600 pixels that provide us with image information. Each of these pixels carries color information in the RGB system, where each color (blue, green, and red) is recorded on 8 bits, totaling 24 bits per pixel. Further multiplying 921,600*24 results in 22,118,400 bits of information—a single web camera delivers approximately 21 megabits at once, and this is just for a single video frame. To produce motion, about 30 such frames per second are needed, resulting in a staggering 632 Mbit/s.
And what about higher resolutions? For 1080p (commonly known as Full-HD resolution), the data rate is approximately 1.42 Gbit/s, and for 4k, nearly 6 Gbit/s. It is evident at the 720p level that few individuals could transmit such an image in “uncompressed” form, and the demands for 4k would be challenging even for some data centers.
What is a video codec
Of course, there is no single way to encode such an image appropriately so that it can be later decoded (the reverse process is decoding). A specific algorithm, or rather a set of them, is necessary. How an image is encoded depends on the codec and the standard that the codec supports. For example, the H.264 standard (MPEG-4 AVC) and its popular implementation x264. However, there is also an alternative implementation of H.264 created by Cisco called OpenH264 or NVENC (for GeForce/Quattro based GPUs from NVIDIA corp), which inherently adheres to the same standard. Different codecs, as well as their standards, will vary in the algorithms used, mechanics, and even things like licensing or performance.
Video codec types
Video codecs are essentially divided into two categories: “lossless” and “lossy.” As the name suggests, lossless codecs do not lose any information that was originally recorded by, for example, a camera. This works identically to the popular ZIP compression format often used to compress attachments before sending them via email. Thanks to such operations, the recipient can read the documents in their unchanged form, often reducing the file size by even 40%.
- Lossless codecs
Lossless codecs are primarily used in video editing and processing. When film material is recorded, it is then cut. Frames are selected, color correction is applied. At this stage, it is crucial that the image is of perfect quality, which is why lossless codecs are found in professional video cameras (RED) or editing software (Final Cut Pro, Adobe Premiere). Examples include Apple ProRes and RedCode RAW.
However, the downside of lossless codecs is their relatively large size, which still makes them unsuitable for distribution over the Internet or on data carriers like DVDs/Blu-Ray. Working with such codecs also requires quite powerful hardware, often equipped with a large amount of RAM or advanced graphics cards. For Apple computers, there are even dedicated accelerators that speed up operations on materials based on lossless codecs, making work on them much more efficient. - Lossy codecs
The second group mentioned are the so-called lossy codecs, where the original material loses some information to achieve a smaller resulting video size. Examples of such codecs include the previously mentioned H.264, as well as its successor H.265, and competing VP8, VP9, AV1. The capabilities of these codecs are vast. For example, the H.264 codec can produce a video stream for 720p resolution at about 3 Mbit/s in decent image quality. We are talking here about reducing the original material by almost 200 times. On the other hand, its successor, the H.265 codec, can produce a stream of identical quality but at only half its bitrate, i.e., about 1.5 Mbit/s.
What is very important to mention at this stage is that, unlike lossless codecs, lossy codecs have a vast number of parameters and settings that directly impact the resulting video stream. These parameters can be broken down into three basic and closely related attributes:
- Image quality – The better the image quality, the larger the resultant size of the video file, for example. However, more advanced profiles can be applied (for instance, for H.264 we have the basic “baseline” profile, the “main” profile, and the “high” profile, which creates the most detailed image). We can attempt to reduce the resultant size for our video, but this, in turn, means a longer encoding process and, in some cases, a greater need for computational power.
- Output size – The higher the bitrate of the stream, the better the potential quality of the image itself. A smaller video size can be achieved by using more aggressive compression algorithms, but again this will require more computational power and potentially generate greater delays.
- Latency – In the case of real-time video streaming, the delays generated by the encoder or transcoder are very important. If we focus on creating the lowest possible delays, the cost will unfortunately be the quality of the image itself. If latency is not our concern (for instance, when creating static content), then this parameter does not play a significant role, and we can achieve much better quality or smaller video file size as a result.
- Image quality – The better the image quality, the larger the resultant size of the video file, for example. However, more advanced profiles can be applied (for instance, for H.264 we have the basic “baseline” profile, the “main” profile, and the “high” profile, which creates the most detailed image). We can attempt to reduce the resultant size for our video, but this, in turn, means a longer encoding process and, in some cases, a greater need for computational power.
Video encoding process
So, what does the video encoding process look like on the inside? Fundamentally, this is a very difficult question because each codec operates and functions differently from the others. Codecs can also be based on hardware solutions, which often enable faster processing. However, we can identify a certain pool of techniques and algorithms that are most commonly used in such a process and discuss what they involve:
- Intraframe & interframe compression
Let’s imagine a picture of a house painted by a small child. Most of these pictures look the same. There’s the sun in one corner, a square house with a sloping roof. There’s a chimney from which smoke is coming out. There is a fence and probably some grass. However, if we look closely at this image, we’ll notice that many elements repeat or are very similar to each other. For example, all the windows are the same. The boards in our fence also “don’t differ much” from each other. Intraframe compression is precisely about identifying such small elements and “unifying them” within a single frame.
The algorithm itself is, of course, more advanced and takes into account, for example, how important (detailed) a given element is in selecting the appropriate size of the unified fragments. The image resulting from the operation of such an algorithm practically does not differ from the original, but such compression allows for a significant amount of space to be saved.
Interframe compression works in similar manner, however, it focuses on identifying common elements between individual frames. In video compression, we usually deal with two types of frames. The first type is the keyframe, or I-frame (Intra-coded frame), which contains complete image information. It is a full picture that can be displayed on our screen. The intermediate frames, or P-frames (Predictive frames), describe only the changes from what was previously shown. For instance, imagine a film featuring a car moving against a blue sky. The intermediate frames would contain information only about the moving car and possibly the road it is traveling on, but not necessarily about the sky, which remains static from this perspective. There are also so-called bidirectional frames, or B-frames (Bidirectional predictive frames), which describe changes not only in relation to the previous frames but also to future frames, allowing for even more efficient compression.

- Transformation functions & quantization
At this stage, we are already delving into deep mathematics, but let’s try to explain in an accessible way what these two processes entail. Let’s start by visualizing these two processes and return to the example with our little house. We have areas on it that are more detailed, like the house itself (e.g., it is made of bricks), and there is grass in front of it. However, the sky in this image constitutes a rather uniform section. The child who painted this drawing was not very careful. A piece of the sky got smeared with a crayon of a different color, there is a fingerprint accidentally left there, and in another place, we find small spots. Transformation functions allow for analyzing areas in the context of their detail and determining whether they are needed and important there, or not at all. The most well-known transformation function is the Discrete Cosine Transform (DCT), used for example in JPEG compression.
Quantization, on the other hand, is usually the second step of this process. Now that we know which details are important and which are not, we can reduce the latter. Here occurs the data thinning, because we replace the original image segment with its simplified version, which, using the previously mentioned intraframe and interframe compression, will allow us to achieve better results.
- Motion estimation and compensation
The next technique worth discussing is motion estimation and compensation. This process involves predicting the movement of blocks of pixels between consecutive frames. The encoder looks for a block in a reference frame (which could be a previous or future frame, depending on the type of frame being encoded) that closely matches a block in the current frame. The difference between these frames, often called the motion vector, represents the shift of pixels from one location to another. This vector is what gets encoded, rather than the entire block of image data, significantly reducing the amount of data that needs to be transmitted.
For example, consider a scene where a bird flies across a static background. Instead of encoding each frame containing the bird and the background independently, motion estimation allows the encoder to recognize that only the position of the bird changes. It then encodes the movement (motion vector) along with any slight changes in the appearance of the bird or background.
Once the motion is estimated and the vectors are encoded, motion compensation is the technique used by the decoder to reconstruct the moving objects in the video. Using the reference frames and the motion vectors, the decoder can predict the position of the moving blocks in the subsequent frames. This prediction is then used to display the video while maintaining fluid motion without the need to encode each frame from scratch.
The use of bidirectional frames (B-frames) enhances this process by allowing the use of both previous and future frames as references. This not only improves the prediction accuracy but also further reduces the data needed for frames where objects move predictably.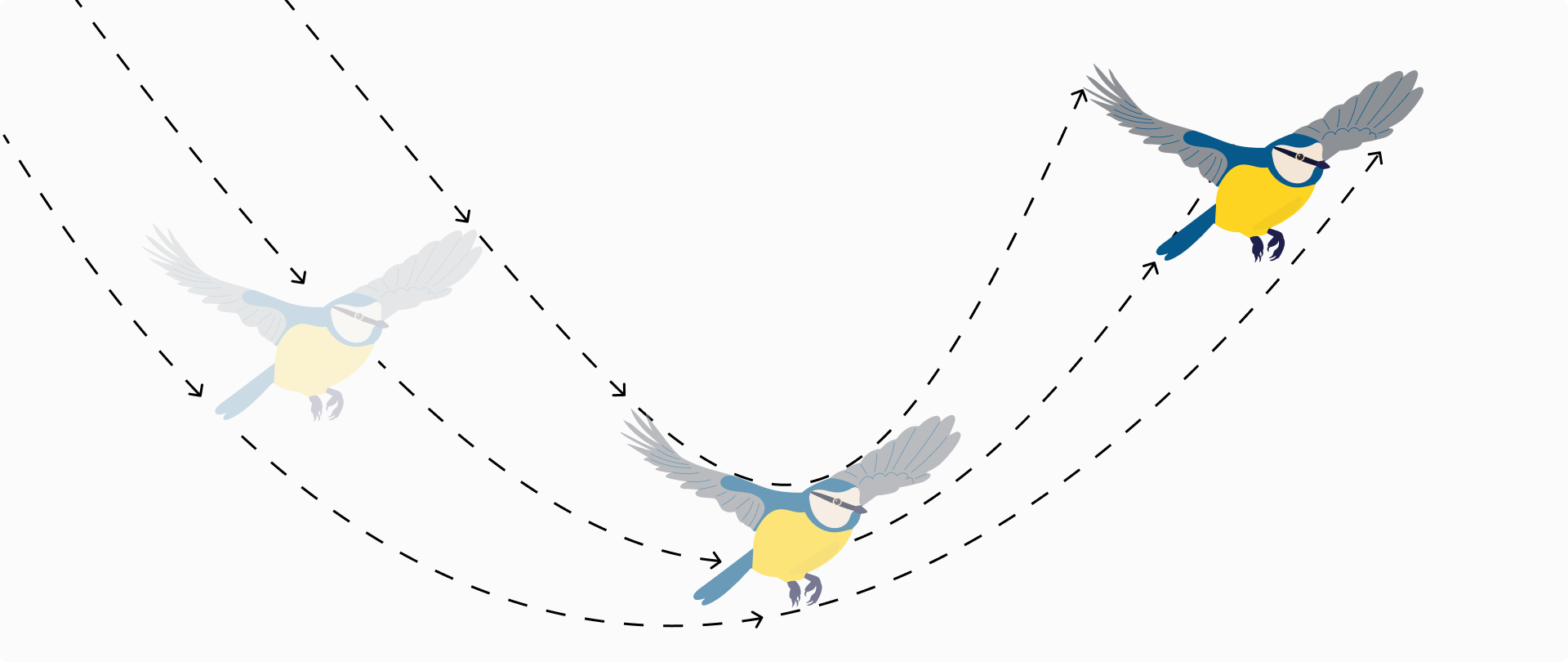
- Entropy encoding
At this stage, the image in our video has already been significantly optimized and compressed. We can now proceed to optimize the data recording itself. This mechanism is very similar to the compression we know from sending attachments in emails. The role of entropy is to find the largest possible repeating fragments and replace them with a certain code, and to combine the small fragments with the large ones.
In video encoding, algorithms such as CAVLC (Context-based Adaptive Variable Length Coding) and CABAC (Context-based Adaptive Binary Arithmetic Coding) are used. The first algorithm is much simpler and is used, for example, by H.264 to record data in lower profiles such as baseline or main. CABAC, on the other hand, is a much more efficient algorithm, but also significantly more computationally demanding. Hence its use in the high-quality high profile. As an interesting fact, it’s worth noting that H.265 uses only and exclusively CABAC.
Video containers
Once we encode our video, we need to place it in some kind of container that ideally would also allow us to combine the image with sound. This is precisely what containers are used for. Nowadays, we most commonly encounter containers based on ISOBMFF (ISO base media file format) such as MP4, 3GP, or Matroska like WebM, MKV. The structure and construction of each are very similar. The role of a container is to indicate where the video and audio data begin, what codec should be used to play the file, where the keyframes are located, and also how many frames per second should be displayed.
Containers greatly facilitate the playback of streams for applications by indicating segments with video settings or specific compression techniques. A large part of this information is not found in the video element itself, but must be added later in order for video playback to be possible at all.
Encoding capabilities in Storm Streaming Server & Cloud Support
Both Strom Streaming Server and Storm Streaming Cloud are equipped with a dedicated video encoding component, which allows for the creation of stream subversions in various resolutions and bitrates, thereby enabling Adaptive Bitrate Streaming functionality. There is also the possibility of using this mechanism to repair damaged streams, or for example, to add missing keyframes. Both solutions support a wide range of codecs such as H.264, H.265, AV1, and VP9.
Summary
In this exploration of video encoding, we’ve navigated through the intricacies of converting raw video into manageable formats that can be easily distributed, stored, and streamed across various platforms. From the data-intensive nature of raw video files to the sophisticated processes involved in compression, video encoding emerges as a critical technology in our digital age. We’ve dissected the roles of different codecs and containers, delved into the technical depths of compression methods, and considered the impact of these technologies on video quality and accessibility.